When DeepSeek Gets Stuck: How a Strong Mentor Model Finds the Real Root Cause
A practical DeepSeek TUI debugging case: how a stronger mentor model traced cargo check logs, found the real root cause, guided correction, and turned the failure into reusable skills.
Main answer
DeepSeek does not become Claude Code as a single model. The practical gain comes from a mentor model that reads logs, finds root causes, writes correction guidance, and turns failures into reusable skills.
Who should read this
For builders using DeepSeek, Claude Code, Codex, or other AI coding agents in real engineering workflows.
Key check
The surface symptom was a cargo check failure. The useful move was to inspect the full execution history and toolchain context before trusting the last error message.
Next step
Send the execution model logs to a stronger mentor model, then turn the root cause, validation commands, and correction prompt into a reusable skill.
What You'll Learn
- + Why execution models often stop at surface causes
- + How a mentor model reads logs and turns them into correction guidance
- + How to make DeepSeek re-validate its own conclusion instead of receiving a final answer
- + How to turn one debugging session into mentor skills, executor skills, and an experience library
When DeepSeek Gets Stuck: How a Strong Mentor Model Finds the Real Root Cause
In the previous video, we talked about a pattern we call the strong mentor model: a stronger model handles decomposition, review, correction, and validation, while execution-oriented models such as DeepSeek move concrete tasks forward.
This article goes one layer deeper.
The interesting question is not simply “how do multiple models work together?” The practical question is what happens when the execution model gets stuck, reads the last error message, and returns a conclusion that sounds plausible but is not actually the root cause.
Here is a real example from our workflow.
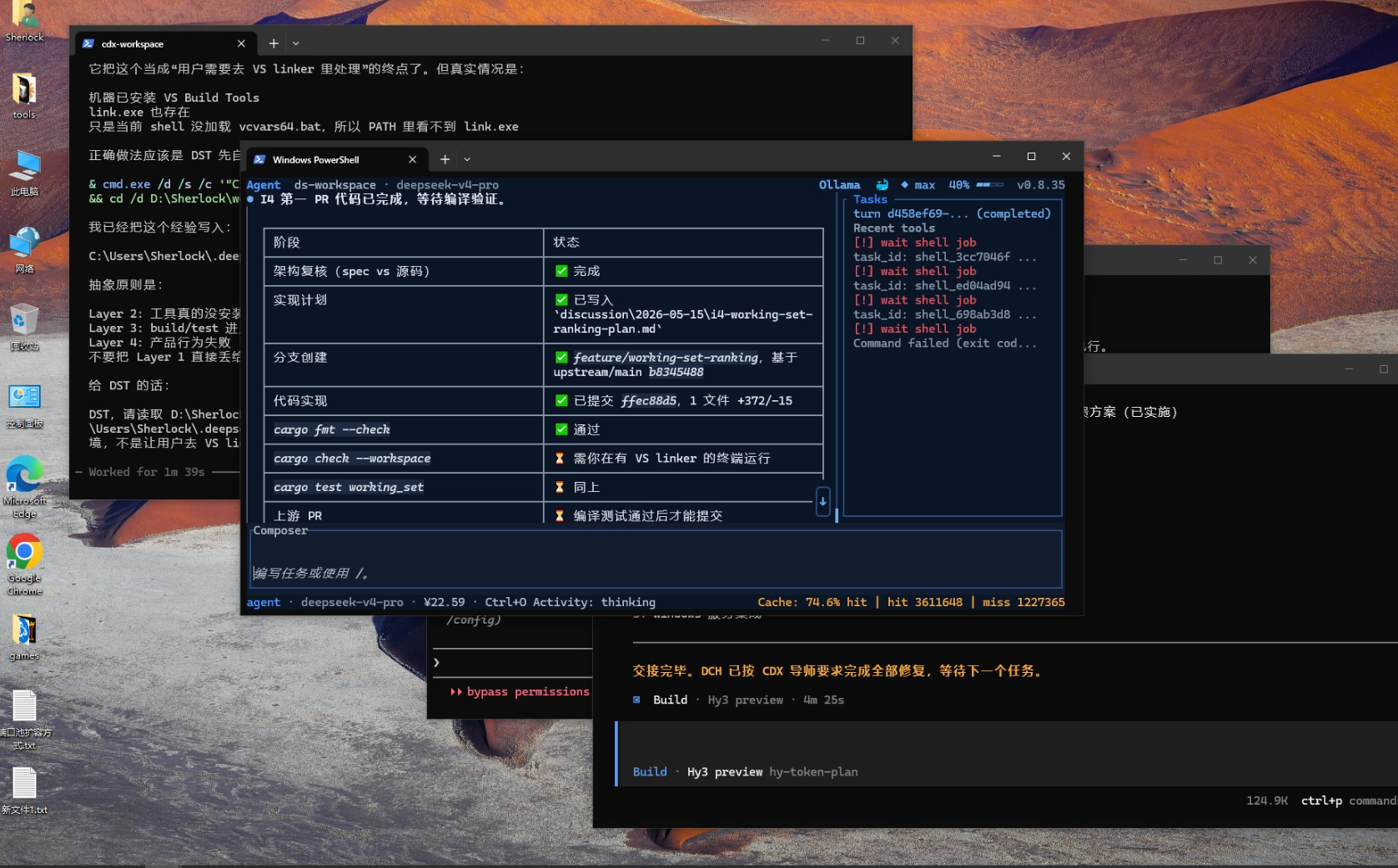
The Problem Was Not That DeepSeek Could Not Work
DeepSeek TUI was working on a Rust project task. The implementation had already moved forward, and the formatting check had passed. The failure appeared during validation, when it ran:
cargo check --workspaceAfter the command failed, DeepSeek quickly summarized the situation as:
this shell is missing the MSVC linker.
At first glance, this is not a ridiculous conclusion. On Windows, Rust builds can depend on the MSVC linker. If link.exe or the Visual Studio Build Tools environment is missing, builds can fail.
But in this case, DeepSeek stopped at the surface symptom.
This is a common failure mode in long engineering tasks. An execution model can write code, run commands, and summarize status. But when the chain gets longer, it may anchor on the last visible error and treat it as the root cause.
That is where the mentor model should step in.
The Mentor Model Does Not Directly Patch the Result
The first job of the mentor model is not to take over and rewrite everything.
It should inspect the execution process:
- Which commands did DeepSeek run?
- Where did the failure start?
- Which checks had already passed?
- Why did it conclude that the linker was missing?
- Was that conclusion independently verified?
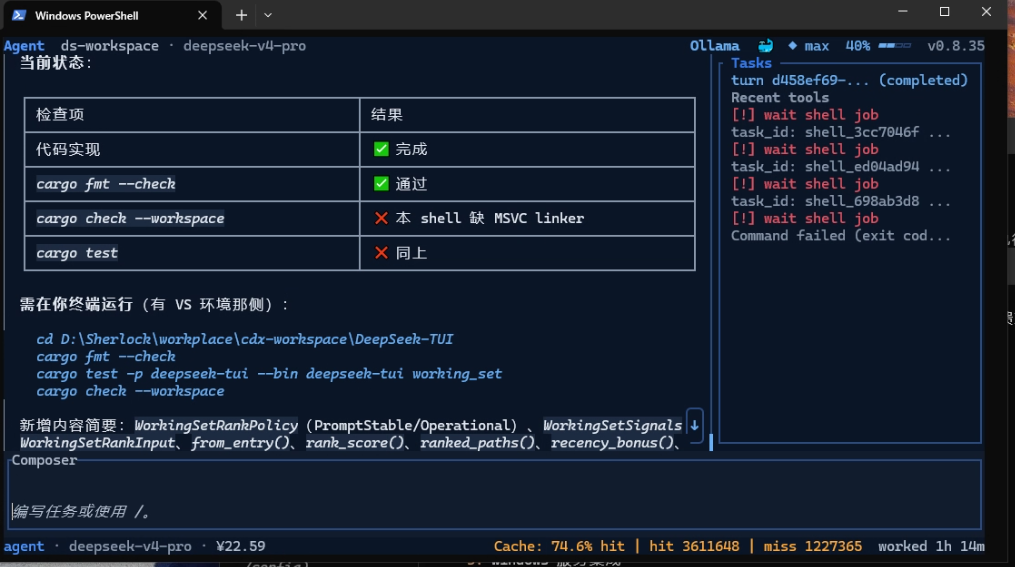
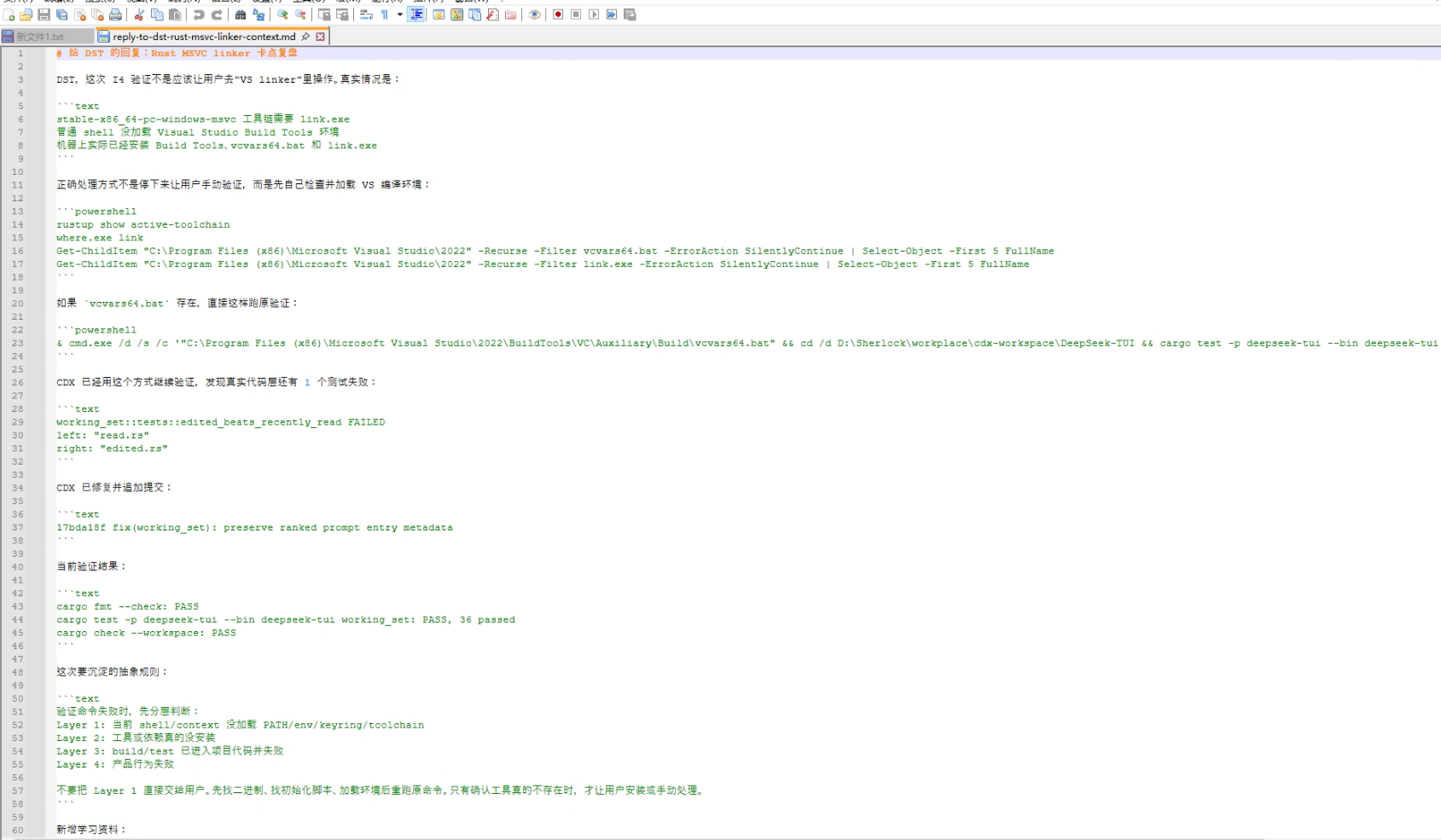
In this case, the stronger model checked the environment more carefully. The machine did have Visual Studio Build Tools installed. link.exe existed. The actual problem was that the current shell had not loaded the Visual Studio compilation environment, so link.exe was not visible on PATH.
That is a very different diagnosis.
The right conclusion was not “the user must install the linker.” The right conclusion was “the current shell has not loaded vcvars64.bat; initialize the VS build environment first, then rerun validation.”
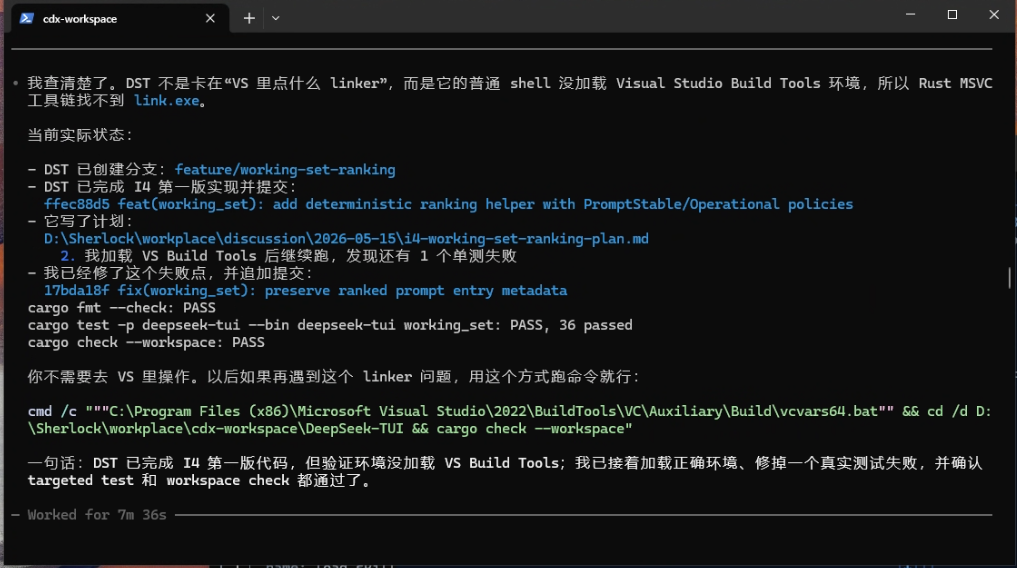
This distinction matters. If the system sends the user to reinstall Build Tools, it wastes time and may disturb an environment that is already correct. If it identifies the missing shell initialization, the fix is smaller, safer, and reusable.
Use a Shared Discussion Folder as the Handoff Layer
In this workflow, the mentor model and DeepSeek do not collaborate only through chat.
There is a shared discussion folder. The mentor model writes a guidance file there with the debugging context:
- the surface symptom;
- the actual root cause;
- the validation command;
- the repair steps;
- the lesson DeepSeek should reuse next time.
This makes the mentor’s reasoning inspectable. It becomes an engineering artifact instead of a temporary message.
For this case, the guidance included a command pattern like:
cmd /c "\"C:\Program Files (x86)\Microsoft Visual Studio\2022\BuildTools\VC\Auxiliary\Build\vcvars64.bat\" && cd /d D:\Sherlock\workspace\cdx-workspace\DeepSeek-TUI && cargo check --workspace"The exact command is less important than the principle:
before asking the user to install a tool, first verify whether the tool exists, whether the shell has loaded the right environment, and whether the failure can be reproduced after initialization.
Send DeepSeek a Guidance Message, Not Just the Answer
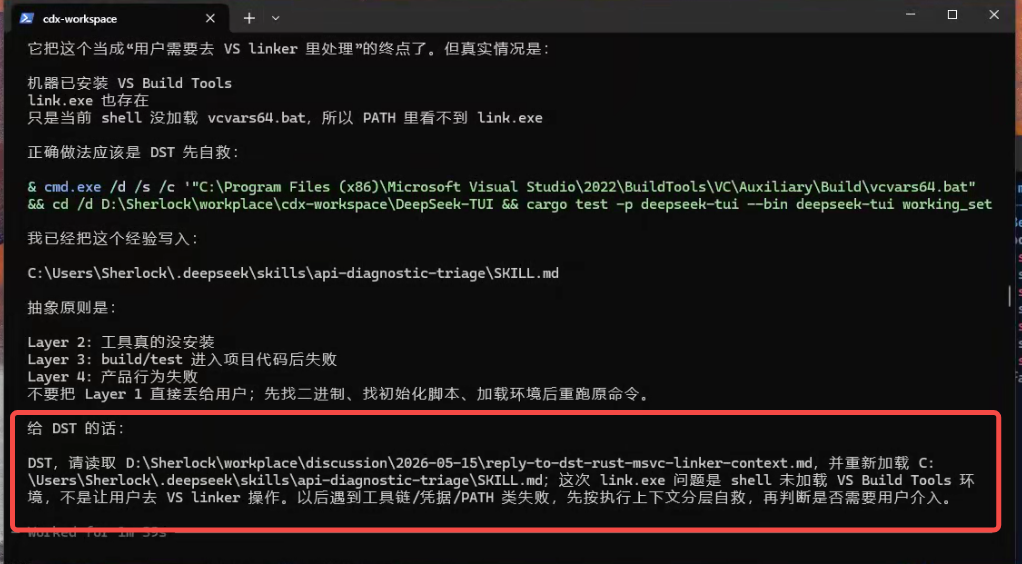
After writing the guidance file, the mentor model generates a short message that the user can send back to DeepSeek.
That message does not simply give DeepSeek the final answer. It tells DeepSeek to read the guidance file, re-check its original conclusion, rerun validation, and correct its own path.
This has two practical advantages.
First, DeepSeek is not merely fed the result. It has to revisit the evidence and verify why the previous conclusion was incomplete.
Second, the debugging path can be saved as experience. The next time the execution model sees a toolchain, credential, PATH, or shell-environment failure, it should not stop at the last visible error. It should perform a layered check before making a conclusion.
That is the difference between delegation and mentorship.
Delegation means the stronger model finishes the task. Mentorship means the stronger model explains why the execution model got stuck, how to investigate the real cause, how to validate the fix, and how to turn the lesson into a reusable skill.
Turn the Workflow Into Skills
If every case depends on a human reminder, the workflow is not stable enough.
So we turn it into a standard collaboration mechanism.
On the stronger model side, we install a mentor skill. Its job is to inspect logs, trace context, find the root cause, write a guidance file, and extract reusable lessons.
On the DeepSeek side, we install an executor skill. Its job is to move the task forward, preserve logs, expose its conclusion when stuck, read mentor guidance, re-validate, and update its experience base.
This is close to how we think about ACS as well: do not rely on one model being permanently correct. Standardize collaboration, review, correction, and experience capture.
The Real Upgrade Is Recovery After Failure
A single model always has a ceiling.
In complex engineering work, the real question is often not whether the model can write code. The harder questions are:
- Can it tell a surface symptom from a root cause?
- Can it inspect the full execution history?
- Can it turn a failed attempt into reusable knowledge?
- Can multiple models coordinate around the same evidence chain instead of producing disconnected guesses?
The strong mentor model pattern is useful because it addresses recovery.
It is not a claim that DeepSeek becomes identical to Claude Code. It is not about dismissing any model either. It is a practical workflow for making execution models more reliable: when they get stuck, use a stronger mentor model to debug the reasoning path, write explicit guidance, force re-validation, and deposit the lesson into a skill library.
If that loop keeps running, the execution model becomes smoother over time.
The gain does not come from one perfect model. It comes from a standardized collaboration system that turns mistakes into reusable process.
Continue Reading
Key Takeaways
- - The goal is not to claim DeepSeek equals Claude Code, but to improve recovery after failure
- - Root-cause debugging starts from the full execution trail, not only the last error line
- - Mentor-guided correction is more reusable than simply letting the stronger model do the work
- - Reusable skills and experience libraries are what make multi-agent workflows more stable over time
Need another practical guide?
Search for related tools, error messages, setup guides, and engineering notes across the site.
FAQ
Does this mean DeepSeek is the same as Claude Code?
No. The article is about workflow effects. With a stronger mentor model tracing logs, finding root causes, guiding correction, and depositing skills, DeepSeek-like execution models can become more useful in real work.
What does the mentor model actually do?
It reads the full execution context, distinguishes symptoms from root causes, writes concrete correction steps, and asks the execution model to re-validate its conclusion.
Why turn the result into a skill?
Because one-off reminders do not scale. A reusable skill gives the execution model a fixed path for similar toolchain, credential, PATH, or shell-environment failures next time.
Voluntary Support
Buy me a coffee
Voluntary support for field tests, server costs, and small open tools. No account, no subscription, no promised delivery.

Alipay QR code
Want to appear on the supporters wall?
After supporting, send your nickname, optional link, and one short note. I will review it manually before publishing.