CodeWhale accepted our PRs: better coding agents need better harnesses
CodeWhale, formerly DeepSeek-TUI, accepted two Kunpeng AI Lab harness PRs. This post explains why patch-impact metadata and Cargo failure summaries help coding agents rely less on guessing and more on engineering signals.
Main answer
CodeWhale, formerly DeepSeek-TUI, accepted two harness PRs from our work: one exposes patch-impact metadata before apply_patch, and the other summarizes Cargo failures into cleaner tool metadata.
Who should read this
For developers who care about coding agents, CodeWhale / DeepSeek-TUI, open-source contribution evidence, and task-level observability.
Key check
The post covers PR #1971 and PR #1973: apply_patch preflight metadata and Cargo failure summaries.
Next step
When evaluating coding agents, look beyond model size and check whether the harness exposes changed paths, failure summaries, human gates, and reviewable task records.
What You'll Learn
- + What the two accepted CodeWhale harness PRs changed
- + Why coding agents need patch-impact metadata and failure summaries
- + Why model capability alone is not enough for real engineering work
- + How harness design turns raw logs and file changes into usable agent signals
CodeWhale accepted our PRs: better coding agents need better harnesses
DeepSeek-TUI has recently gone through an important update. It now has a new name, CodeWhale, and two harness-related PRs from our work have been accepted by the maintainers.
This does not look like a flashy product change. It is not a new screen, and it is not a new button. A user may open the tool and not notice the change immediately.
But if you have used coding agents on real projects, this kind of change matters. The hard part is not only whether the model can generate code. The agent also needs to know what it changed, why a test failed, and where it should look next.

What changed in CodeWhale
The two accepted PRs improve the harness around the agent:
- PR #1971 exposes
apply_patchpreflight metadata, so before the agent edits files, it can see which paths the patch is expected to affect. - PR #1973 summarizes Cargo failures in tool metadata, so a long failure log can be turned into a shorter signal the agent can reason about.
If the model is the brain, the harness is the workbench between that brain and the engineering scene. A weak workbench leaves the model guessing. A clearer workbench gives it better signals.
When people discuss AI coding tools, they often start with model capability: is the model stronger, is the context longer, can it write more code automatically?
Those questions matter. But in day-to-day engineering, another question matters just as much: does the tool turn the task scene into something the model can understand, trace, and review?

These PRs are not about writing more code
The first change is simple: before applying a patch, tell the agent which paths the patch will touch.
That sounds small, but it affects the next decision. If a patch changes a config file, a test file, and a core logic file, where should the agent inspect first after a failure? If path information is missing, the agent can easily spend time in the wrong place.
The second change is about Cargo failure logs.
Build and test logs can be long. The useful part may be buried inside dozens or hundreds of lines. A human engineer filters out noise almost automatically: error type, likely location, useful hint, next check. An agent that receives one raw blob of log text can be pulled away by noise.
The value of this change is not that the harness makes decisions for the agent. It organizes the scene so the agent can make a better next move.

Why this matters for AI replacing work
This also connects to a bigger question: what kind of work is AI actually starting to replace?
In programming, I do not think the first thing being replaced is complete engineering judgment. Not yet.
What is easier to automate first is the repeated, fragmented work around engineering judgment: collecting changed-file context, reading long logs, summarizing failure causes, and listing the next possible checks.
Those tasks are not meaningless. They take attention. But they are not the same as deciding the product goal, choosing the tradeoff, or accepting the risk.
The important point is that AI does not become useful in a vacuum. It needs an environment that provides clean signals.
If a tool throws a long log at the model and hopes the model reconstructs all the context, that is mostly a bet on guessing ability. If the tool can say what changed, where the failure is concentrated, and what evidence should guide the next step, the agent becomes more stable.
So the shift is not “programmers are immediately replaced.” A more practical view is that parts of context cleanup, log triage, and first-pass failure analysis are becoming easier to automate.
What developers can take from this
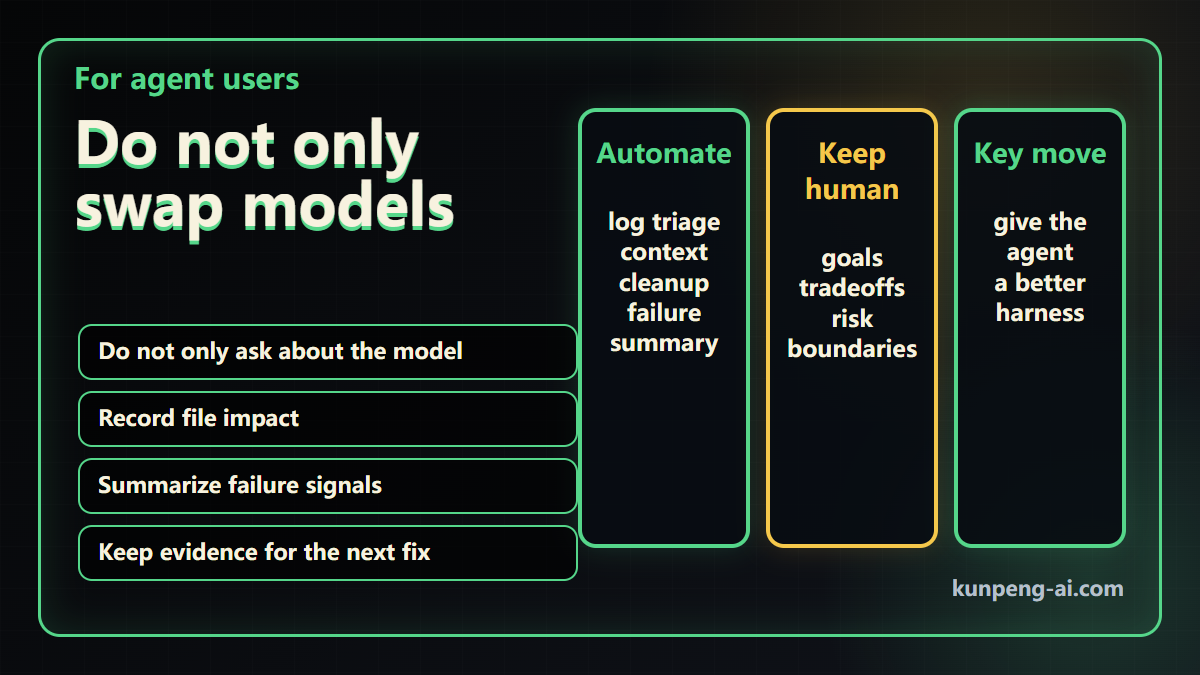
For anyone using coding agents, the takeaway is direct: do not only ask whether the model is strong. Ask whether you have given it a proper harness.
A useful harness should answer questions like these:
- Before the agent modifies files, can it know which files may be affected?
- After a test fails, can the failure become a clean signal instead of raw noise?
- Can the next fix continue from evidence instead of starting over?
- Can the system mark where human judgment is still required?
- After the task ends, is there a record that can be reviewed?
These questions are less exciting than “switch to a stronger model.” They are also closer to real productivity.
In engineering work, model capability matters. But what the model can see, how it calls tools, and what feedback it receives after failure matter too.
What our contribution shows
The accepted PRs do not prove that we wrote a huge amount of code. They show that the maintainers agreed with a direction: coding-agent toolchains need more than surface features. They also need observability at the task level.
A good coding agent should not only generate code. It should know what it changed, why a failure happened, and what should be checked next.
That is why this CodeWhale update is useful. It moves the agent a step away from “keep writing by instinct” and toward “continue with evidence.”
The larger lesson
Progress in AI coding tools does not always arrive as a dramatic new feature. Sometimes it is a clearer patch-impact signal, a cleaner failure summary, or a task scene that can be reviewed later.
Those lower-level changes are what help an agent move from answering to doing.
So when we talk about what AI will replace, it helps to make the question more specific. It is not replacing complete engineering judgment all at once. It is first replacing some repeated context organization, log filtering, and first-pass debugging work.
The part that remains human is still important: goals, tradeoffs, risk control, and deciding how the tool should fit into the workflow.
That is the main lesson I take from these CodeWhale PRs: do not only wait for the model to become smarter. Make the task scene clearer.
Key Takeaways
- - The contribution is two accepted harness/tooling PRs, not a claim that Kunpeng AI Lab controls CodeWhale.
- - Better coding agents need clearer task context, not only larger models.
- - AI is more likely to automate context cleanup, log triage, and first-pass debugging before it replaces complete engineering judgment.
Need another practical guide?
Search for related tools, error messages, setup guides, and engineering notes across the site.
FAQ
What is CodeWhale?
CodeWhale is the renamed DeepSeek-TUI project. This article focuses on two accepted harness-related PRs.
Do these PRs mean AI can replace programmers now?
No. They show how coding-agent workflows can automate context cleanup, log triage, and first-pass failure analysis. Goals, tradeoffs, and risk control still need human judgment.
What is the scope of this contribution?
The scope is two concrete harness improvements: apply_patch preflight metadata and Cargo failure summaries. It should not be overstated as control over the whole CodeWhale project.
Voluntary Support
Buy me a coffee
Voluntary support for field tests, server costs, and small open tools. No account, no subscription, no promised delivery.

Alipay QR code
Want to appear on the supporters wall?
After supporting, send your nickname, optional link, and one short note. I will review it manually before publishing.