Opus 4.8 蒸馏了 Qwen 和 DeepSeek?我们这次实测没有复现
我们在 2026 年 5 月 30 日用 Claude Code 做了一次 Opus 4.8 入口测试:本次素材没有复现 Opus 4.8 自称 Qwen 或 DeepSeek,同时记录了 Claude Code 升级报错由 Codex 协助排查的过程。
查找相关文章
输入工具名、术语或排障信息,直接找到站内相关内容。
核心结论
在这次 2026 年 5 月 30 日的 Claude Code 实测素材里,我们没有复现 Opus 4.8 自称 Qwen 或 DeepSeek 的情况。
适合谁读
适合关注 Claude Opus 4.8、Qwen、DeepSeek、Claude Code 与多 Agent 排障流程的开发者和 AI 工具用户。
关键判断
测试问题是“你是什么大模型?”,本次回答自称 Claude Opus 4.8,并说明运行在 Claude Code 环境里。
下一步
不要把单次身份回答当成训练来源鉴定;后续应继续记录版本、环境、提示词、截图和真实任务表现。
你将学到
- + 这次 Opus 4.8 实测到底复现了什么、没有复现什么
- + 为什么单次模型自我身份回答不能证明训练来源
- + Claude Code 升级报 spawn EBUSY 时,如何区分账号网络问题和本地组件问题
- + 为什么普通用户最好准备两个以上 coding agent 互相排障
Opus 4.8 蒸馏了 Qwen 和 DeepSeek?我们这次实测没有复现
最近关于 Claude 最新 Opus 4.8,有一个很容易传播的说法:它是不是蒸馏了 Qwen 或 DeepSeek?
这个问题有流量,也有争议。但如果只转述传言,价值不大。我们这次做了一轮很直接的实测:先把 Claude Code 跑起来,再问 Opus 4.8 一个最朴素的问题:你是什么大模型?
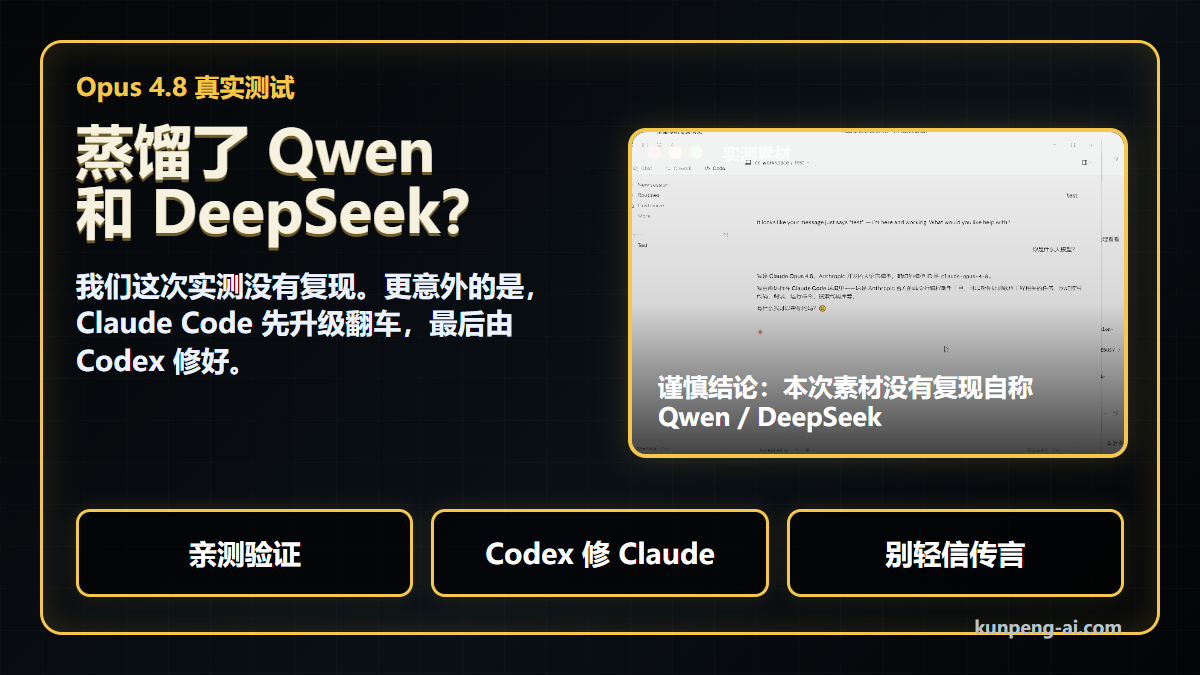
先说结论:在 2026 年 5 月 30 日这次素材里,我们没有复现 Opus 4.8 自称 Qwen 或 DeepSeek 的情况。
这句话需要说严谨一点:这不是证明“网上所有说法都错了”,也不是证明模型训练来源没有任何争议。它只能说明,在我们这次本地 Claude Code 实测里,没有看到那个现象。更有意思的是,真正开始测模型之前,Claude Code 升级先翻车了,最后是 Codex 帮我们把 Claude Code 修好的。
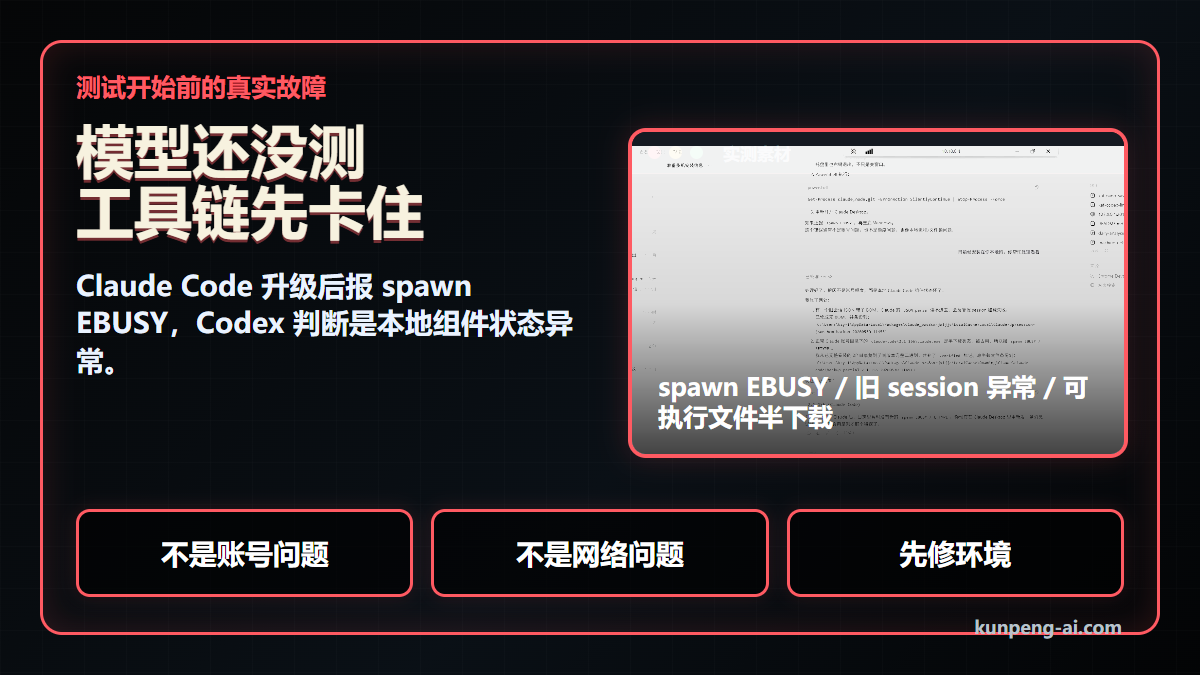
测试一开始,Claude Code 先报错
我们原本想直接测试 Opus 4.8,结果 Claude Code 升级后先报了 spawn EBUSY。
这类问题很容易被误判。很多人第一反应会去查账号、网络、订阅状态,或者怀疑模型服务不稳定。但这次 Codex 给出的判断更接近本地工具链问题:不是账号问题,也不是网络问题,而是 Claude Code 本地组件状态异常。
具体表现包括两个方向:
- 一个旧 session 文件解析异常;
- 一个 Claude Code 可执行文件处在半下载、被占用或状态不完整的情况。
也就是说,模型还没开始测,工具链先卡住了。把这些本地组件问题处理掉之后,Claude Code 才重新跑起来。
这个过程反而很真实。普通人用 AI 工具时,遇到的经常不是演示视频里那种丝滑流程,而是升级失败、组件损坏、本地环境卡住。你以为是模型不行,最后发现是工具链坏了。
真正开始问 Opus 4.8
Claude Code 修好以后,我们才开始真正测试 Opus 4.8。
问题很直接:
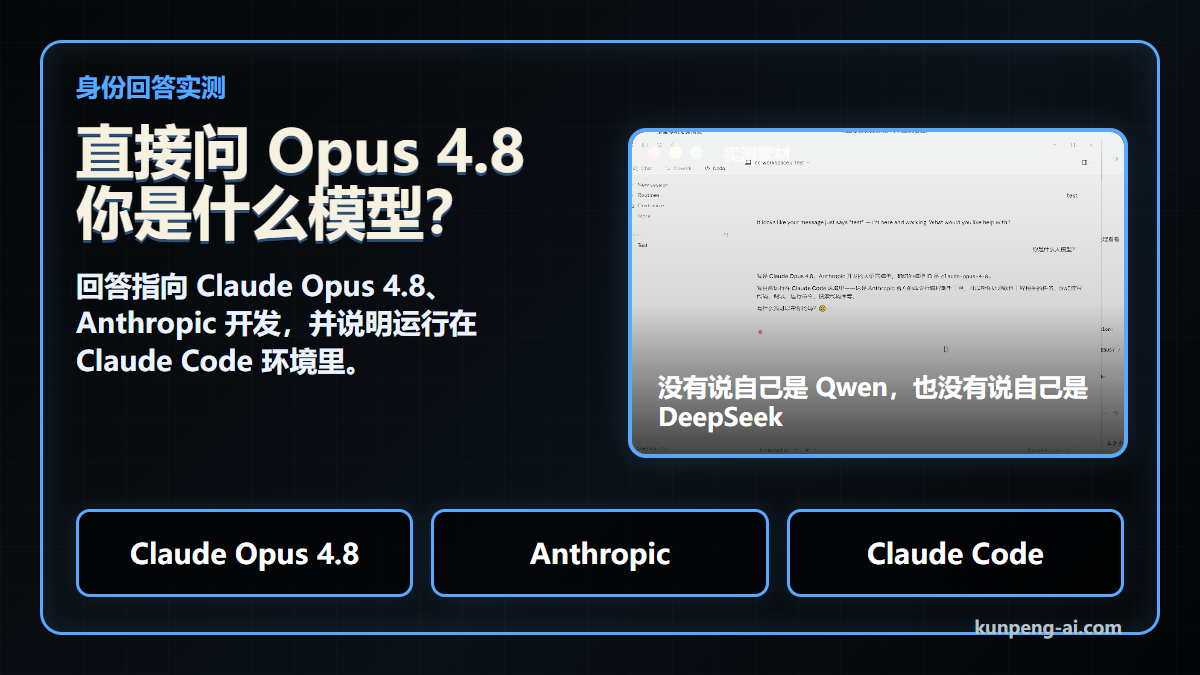
你是什么大模型?这次回答里,它说自己是 Claude Opus 4.8,是 Anthropic 开发的大语言模型,并且运行在 Claude Code 环境里。
在这段素材中,它没有说自己是 Qwen,也没有说自己是 DeepSeek。
所以对开头那个问题,我们只能给一个克制结论:
本次实测没有复现 Opus 4.8 自称 Qwen 或 DeepSeek 的情况。
这个结论不该被夸大。模型是否有蒸馏、借鉴、数据污染、评测误读,需要更多证据。单次自我身份回答也不是严格的训练来源鉴定方法。但当网上出现一个很强的判断时,至少应该先用可复现的方式去验证,而不是只跟着截图和情绪跑。
这件事对普通人有什么启发
我觉得这次测试最值得记录的,不只是 Opus 4.8 怎么回答,而是工具链怎么翻车、又怎么被另一个 Agent 修好。
现在很多 AI 工具更新很快,新模型发布、插件升级、CLI 更新、桌面端更新,都可能带来本地环境问题。你遇到的未必是“模型能力不行”,也可能只是本地组件坏了。
所以电脑上最好不要只装一个 Agent。
至少准备两个以上,比如 Claude Code、Codex 这类工具,可以互相排查问题:
- Claude Code 出问题,可以让 Codex 帮你看日志、拆原因、判断是账号问题还是本地组件问题;
- Codex 遇到问题,也可以反过来让 Claude 分析错误信息;
- 当一个工具链卡住时,另一个 Agent 可以帮你保留判断能力,而不是只能手动猜。

另一个启发是:不要轻易相信未验证的信息。
看到“某个模型蒸馏了谁”“某个模型套壳了谁”,可以先保留怀疑,但不要马上当结论转发。更有价值的做法是自己去问、去测、去看真实输出。如果有条件,就记录版本、环境、提示词和截图,让判断建立在证据上。
后续我们会继续测什么
这次只是 Opus 4.8 的一个入口测试。后面更值得测的是它在真实 Claude Code 工作流里的表现:
- 修复复杂报错时,能不能抓到关键证据;
- 修改真实项目代码时,是否能保持上下文一致;
- 长任务里会不会丢目标、误改文件或重复劳动;
- 和 Codex、其他 Agent 互相协作时,谁更适合做排错、谁更适合做实现;
- 在多轮问答里,身份回答和能力边界是否稳定。
对普通用户来说,模型评测不该只看榜单和传言。更应该看它能不能在你的真实任务里帮你解决问题。
这也是我们接下来会继续做的方向:少一点站队,多一点实测;少一点结论先行,多一点可检查的过程。
继续阅读
要点总结
- - 本次素材只支持一个克制结论:没有复现 Opus 4.8 自称 Qwen 或 DeepSeek。
- - 这不是对训练来源、蒸馏关系或所有网络传言的最终证明。
- - 真实 AI 工具使用中,工具链故障和本地组件状态同样值得记录。
常见问题
这次测试能证明 Opus 4.8 没有蒸馏 Qwen 或 DeepSeek 吗?
不能。它只能说明在这次本地 Claude Code 实测素材里,没有复现 Opus 4.8 自称 Qwen 或 DeepSeek。训练来源、蒸馏关系和数据污染需要更多证据。
为什么文章还记录 Claude Code 的 spawn EBUSY?
因为测试开始前工具链先出问题,Codex 的排查显示更像本地组件状态异常。这是普通用户做 AI 工具实测时经常遇到的真实场景。
普通用户应该怎么验证类似传言?
先保留怀疑,记录日期、版本、环境、提示词和输出截图,再用可复现流程测试。不要把单张截图或单次回答直接升级成绝对结论。
