OpenClaw PR #76024 合并复盘:一次 Windows EBUSY 内存索引修复如何进入上游
OpenClaw 官方已合并 kunpeng-ai-lab 提交的 PR #76024。本文复盘这次 Windows memory atomic reindex 在短暂文件锁下可能触发 EBUSY / EPERM / EACCES 的问题、修复边界、测试验证、review 跟进和最终合并过程。
需要继续找相关内容?
如果你想继续查工具名、术语、对比页或相关问题,可以直接搜全站,不用回到博客列表页重找。
核心结论
OpenClaw 官方已合并 PR #76024。这个补丁解决的是 Windows 环境下 memory atomic reindex 交换 SQLite index 文件时,短暂文件锁可能导致 fs.rename 返回 EBUSY / EPERM / EACCES 的问题。
适合谁看
适合关注 OpenClaw、Windows AI Agent 稳定性、上游 PR 协作、偶发文件锁问题,以及想看真实工程修复如何进入官方主线的开发者。
关键判断
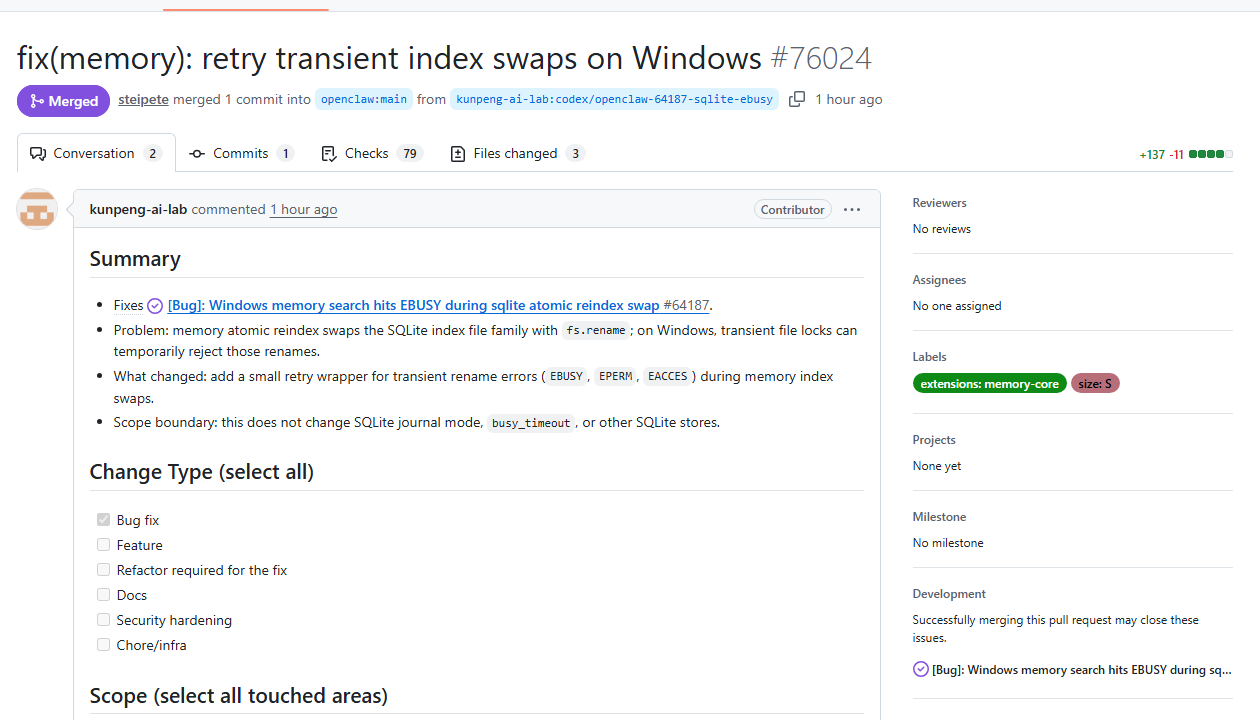
PR #76024 merged=true,merged by steipete,merged at 2026-05-02 18:07:49 +08:00,merge commit f3fd0eedff215967eb75361d241dd5e6cea602e8;GitHub check runs 为 79 completed、71 success、8 skipped、0 failure。
下一步建议
如果你也在 Windows 上运行 OpenClaw 或其他 Agent 工具,可以重点关注 gateway、memory、文件锁、后台进程和升级后的状态恢复问题。排障记录最好包含复现条件、验证命令、补丁边界和上游链接。
你将学到
- + PR #76024 解决了 OpenClaw 在 Windows 上的哪个具体边界问题
- + 为什么这次修复选择有限 retry,而不是扩大到 SQLite 全局配置
- + 如何把偶发 Windows 文件锁问题整理成上游可 review 的补丁
- + 如何用 issue、PR、bot review、CI、merge commit 组成工程证据链
- + 写上游贡献复盘时,如何避免把一个小修复夸大成大而全方案
OpenClaw PR #76024 合并复盘:一次 Windows EBUSY 内存索引修复如何进入上游
这篇文章只讲一件事:我们提交到 OpenClaw 的 PR #76024 已经被官方合并,它修复了 Windows 上一个具体的 memory atomic reindex 文件交换问题。
这个问题不大,但很典型。它不是“Windows 全面稳定性修复”,也不是“OpenClaw 所有内存索引问题的最终答案”。它处理的是一个很窄的边界:OpenClaw 在交换 SQLite index 文件时,如果 Windows 短暂文件锁让 fs.rename 返回 EBUSY、EPERM 或 EACCES,原流程可能直接失败。
这次补丁做的事情,是在这个文件交换边界上增加有限 retry,让短暂文件锁有机会自行恢复,同时不改动更大的 SQLite 行为。
| 证据项 | 信息 |
|---|---|
| PR | openclaw/openclaw#76024 |
| 关联 issue | openclaw/openclaw#64187 |
| 状态 | Merged / Closed |
| 合并人 | steipete |
| 合并时间 | 2026-05-02 18:07:49 +08:00 |
| Merge commit | f3fd0eedff215967eb75361d241dd5e6cea602e8 |
| Head commit | 2b53246ab5cc75a0e46309c52cdc653afcc40d04 |
| CI 状态 | 79 completed,71 success,8 skipped,0 failure |
先说问题边界
OpenClaw 的 memory atomic reindex 流程会先构建一份临时索引,再把 index.sqlite、index.sqlite-wal、index.sqlite-shm 这一组文件交换到正式位置。
在 Windows 上,文件锁比很多开发者预期得更严格。运行时、杀毒软件、索引器,甚至某个短暂打开文件的进程,都可能让 rename 在某一瞬间失败。
这类问题麻烦在于它通常不是稳定复现的语法错误,而是偶发的系统行为。今天失败,明天可能正常;一台机器失败,另一台机器可能碰不到。
所以这次 PR 没有扩大修复范围。它没有改:
- SQLite journal mode
- 全局
busy_timeout - 其他 storage 模块
- gateway 启动逻辑
- Windows 进程管理策略
它只处理 memory atomic reindex 的文件交换阶段。
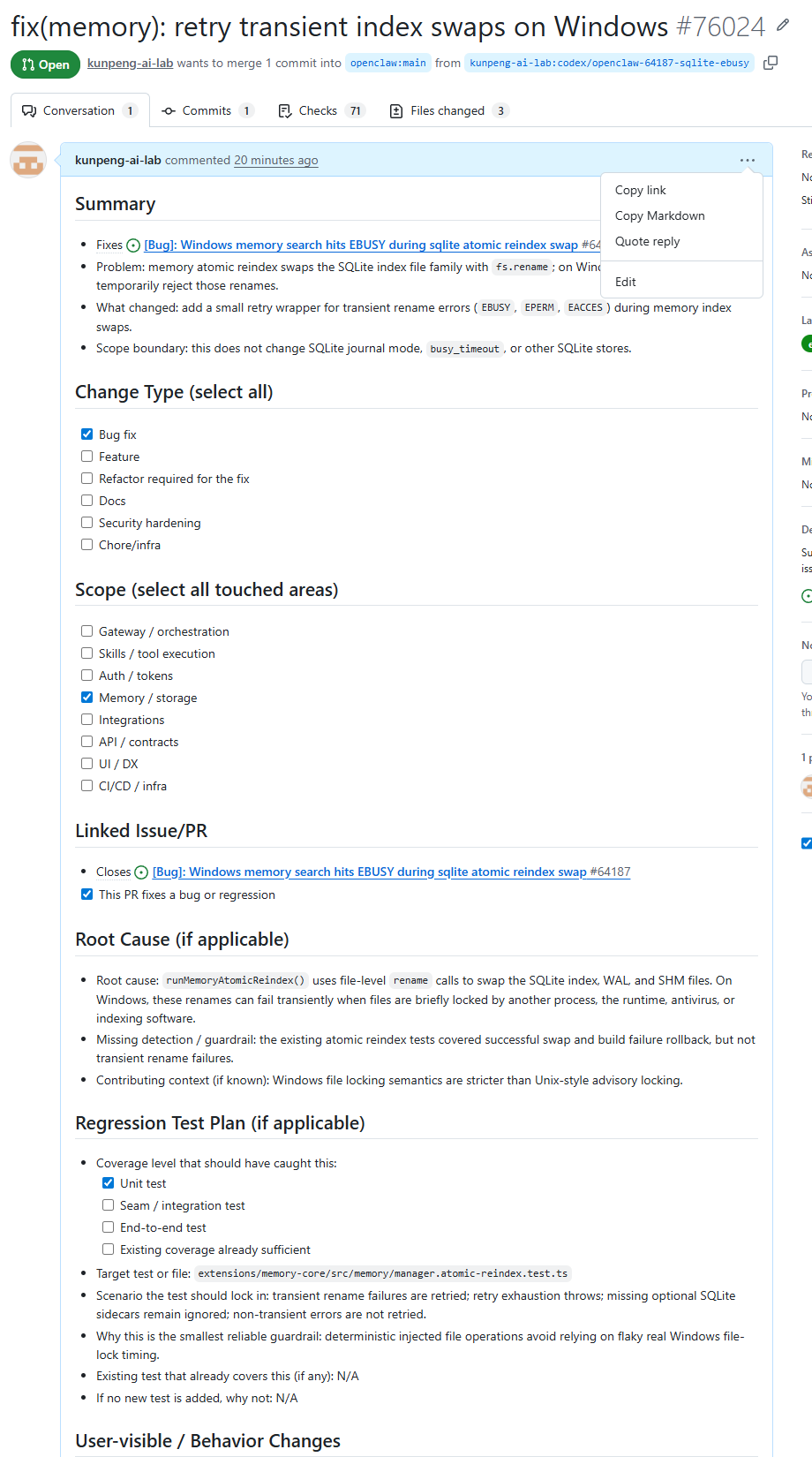
如果要一句话概括这次修复,我会这样写:
修复 OpenClaw 在 Windows memory atomic reindex 文件交换阶段,遇到短暂 EBUSY / EPERM / EACCES rename 失败时可能直接中断的问题。
这个边界看起来窄,但正因为窄,才更容易被测试、review 和合并。
补丁怎么做
PR 标题是:
fix(memory): retry transient index swaps on Windows核心思路很朴素:只对 transient file swap failure 做小范围 retry。
具体来说:
- 只处理
EBUSY、EPERM、EACCES - retry budget 很小:5 次,25ms linear wait,最大约 375ms
- 保留原有 ENOENT sidecar 逻辑
- 不把其他错误吞掉
- 不把这个行为扩散到其他 store
这类补丁最怕“为了修一个偶发问题,引入一个更难解释的新行为”。所以这里宁愿保守一点:只处理明确属于 transient lock 的错误类型,其他异常继续按原逻辑暴露。
为什么不是本地 workaround
遇到 Windows 文件锁问题,本地 workaround 很常见,比如删临时文件、重启进程、重新跑脚本。
这些方法有时能救急,但它们很难变成上游资产。真正能被社区复用的,是把问题整理成维护者可以 review 的形态:
- 关联具体 issue:
#64187 - 说明 root cause:Windows 短暂文件锁会让
fs.rename失败 - 说明修复范围:只处理 memory index swap,不碰全局 SQLite 行为
- 补测试:覆盖 transient retry、retry 耗尽、sidecar 文件缺失、非 transient error
- 补 changelog:按官方要求补充变更记录
- 在 PR 中写清本地验证命令和结果
中间 bot review 提醒需要 maintainer review,也指出了这个 PR 的修复范围和风险边界。
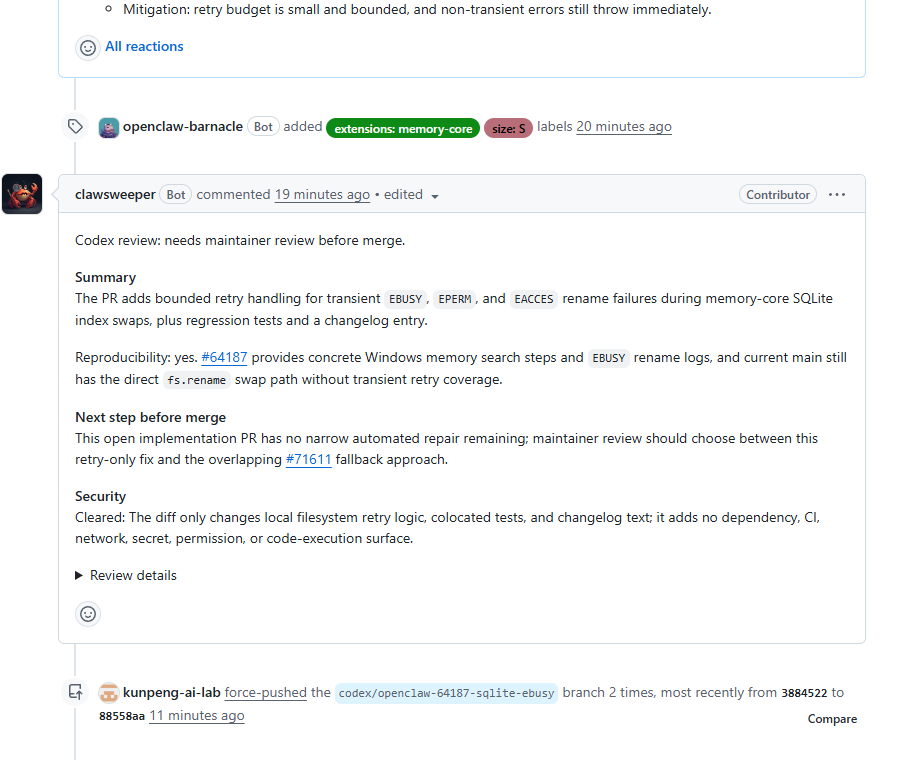
后续我们 rebase 到最新 origin/main,补上 changelog entry,处理冲突,再用 --force-with-lease 更新分支,并把本地验证结果写回 PR。
这也是这次复盘里最值得留下的一点:上游贡献不是把代码推上去就结束。维护者真正需要的是你把“为什么改、改了哪里、怎么验证、风险在哪里”交代清楚。
CI 状态要写准确
这次 head commit 的 GitHub check runs 汇总是:
| 项目 | 数量 |
|---|---|
| total check runs | 79 |
| completed | 79 |
| success | 71 |
| skipped | 8 |
| failure | 0 |
| cancelled | 0 |
所以我不会写“全部 CI 成功”。因为里面有 8 项是 skipped。
更准确的表达是:该 commit 的 79 个 check runs 已完成,其中 71 个 success、8 个 skipped,未看到 failure 或 cancelled。
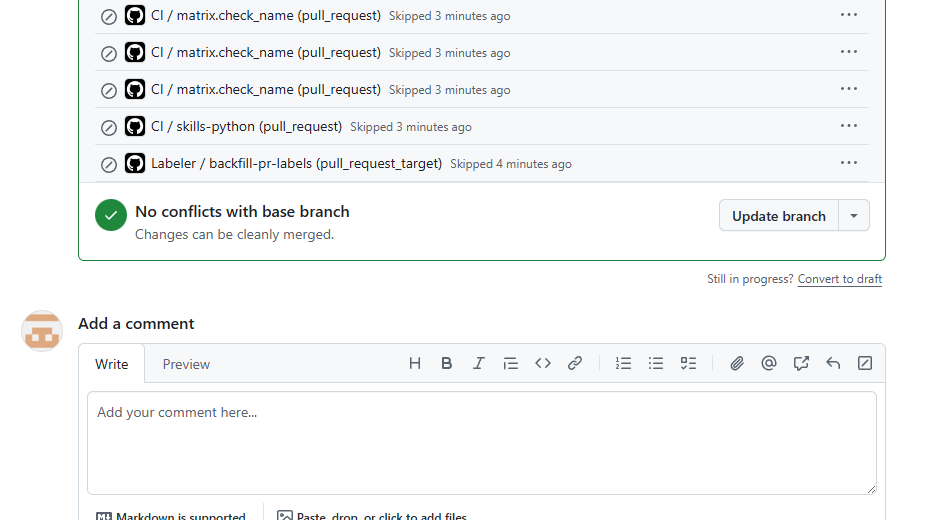
这种表述不花哨,但它更可靠。工程复盘里最重要的不是好看,而是可核对。
官方合并意味着什么
最终,PR #76024 被 OpenClaw 官方合并。
这说明这条链路闭合了:
真实 Windows 问题
-> issue 记录
-> 最小修复
-> 测试验证
-> bot review
-> 补充说明
-> CI 无失败
-> 官方合并
-> merge commit 进入主线对开发者来说,这比单纯写一篇“我遇到过这个问题”的经验文更扎实。
因为补丁进入了上游主线,后续使用 OpenClaw 的其他 Windows 用户也可能从这个修复中受益。即使他们不知道 PR #76024,也会在升级后间接受到影响。
给 OpenClaw 用户看的影响
如果你只关心使用 OpenClaw,可以这样理解:
Windows 上 memory index 重建时,如果文件交换阶段遇到短暂文件占用,OpenClaw 不会因为第一次 rename 失败就立刻放弃,而是会在很短的时间窗口内重试。
这不代表所有 Windows 问题都解决了。
它不处理:
- 所有 SQLite 读写问题
- 所有 Windows 文件系统问题
- 所有 OpenClaw memory search 问题
- gateway 启动失败
- 18789 listener 问题
- 企业环境里的权限策略问题
它处理的是:
memory atomic reindex
-> file swap
-> transient rename failure
-> EBUSY / EPERM / EACCES这个边界越清楚,用户对修复的预期就越不容易跑偏。
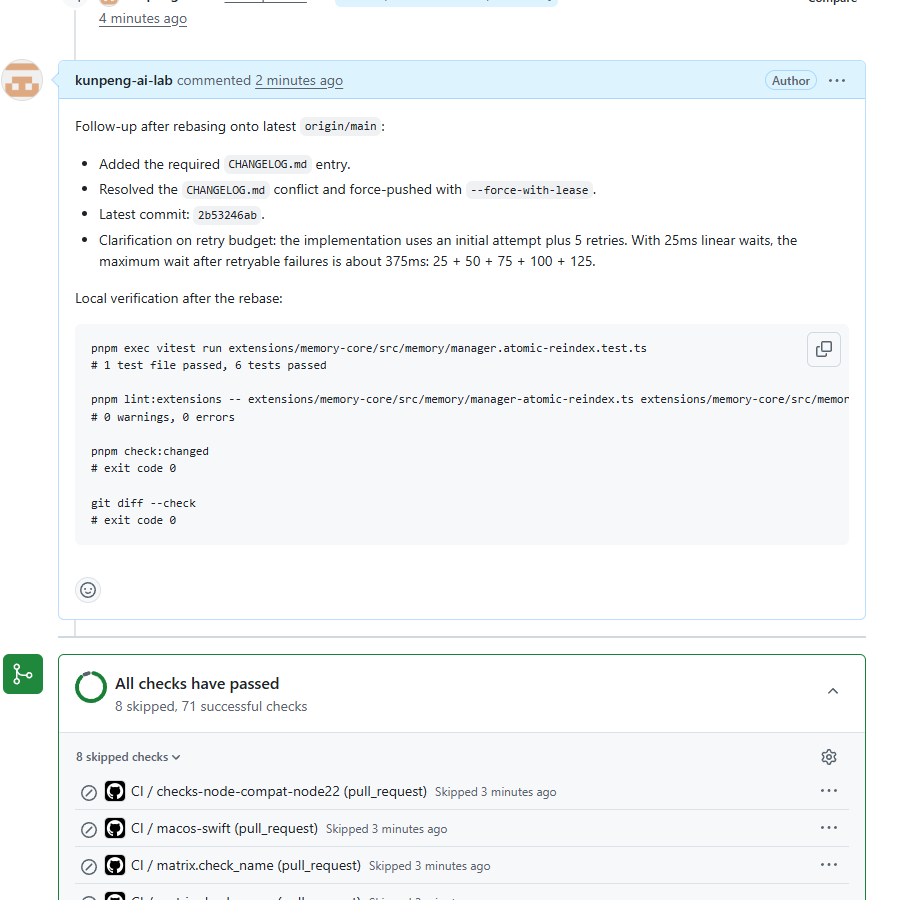
本地验证记录
本地验证命令包括:
pnpm exec vitest run extensions/memory-core/src/memory/manager.atomic-reindex.test.ts结果:
1 test file passed
6 tests passedNode 22 环境也重新跑过:
$env:Path = 'D:\nvm4w\nodejs;' + $env:Path
node --version
pnpm exec vitest run extensions/memory-core/src/memory/manager.atomic-reindex.test.ts结果:
v22.22.2
1 test file passed
6 tests passed还跑了:
pnpm lint:extensions -- extensions/memory-core/src/memory/manager-atomic-reindex.ts extensions/memory-core/src/memory/manager.atomic-reindex.test.ts
pnpm check:changed
git diff --check对应结果是:
0 warnings, 0 errors
exit code 0
exit code 0这些命令不是装饰。它们让这次修复可以被别人复查,也让后续复盘不只依赖记忆。
这类上游贡献怎么沉淀
这次 PR 已经加入长期更新的上游贡献专题:
后续类似记录会继续按工程证据来整理:
- 问题截图
- 复现条件
- 本地验证命令
- 补丁说明
- PR / issue 链接
- 官方回复
- CI 状态
- 最终合并或关闭状态
对我们自己来说,这类记录也是一种训练:少写口号,多留证据;少做泛化判断,多讲具体边界。
如果你也在做 AI Agent 工具,尤其是在 Windows 上做长期运行,我建议每次排障都按这个格式沉淀:
问题截图
-> 复现步骤
-> 本地验证命令
-> 修复说明
-> 上游链接
-> 官方回复
-> 最终状态这比散落在聊天记录里的经验更耐用。
继续延伸
要点总结
- - 这是一个真实 Windows 问题被整理、修复、验证并进入 OpenClaw 官方主线的案例。
- - PR #76024 的边界很清楚:只修复 memory atomic reindex file swap 中的 transient rename failure,不泛化成所有 Windows 稳定性问题。
- - 上游贡献的关键不是把代码推上去,而是把原因、范围、测试、风险和后续验证讲清楚。
- - 官方合并、issue 关联、CI 无失败、本地验证命令和截图证据放在一起,才是一份可复盘的工程记录。
常见问题
PR #76024 是不是已经被 OpenClaw 官方合并?
是。GitHub 页面显示 PR #76024 已 merged,merged by steipete,合并时间为 2026-05-02 18:07:49 +08:00。
这个 PR 解决了 OpenClaw 所有 Windows 问题吗?
没有。它解决的是 memory atomic reindex 文件交换阶段的短暂 rename 失败问题,错误类型包括 EBUSY、EPERM、EACCES。
为什么不直接改 SQLite journal mode 或 busy_timeout?
因为这次问题集中在文件交换阶段的 transient rename failure。补丁保持在最小边界内,只对相关 rename 操作做有限重试,避免引入更大的存储行为变化。
