Claude Fable 5 实测:别被 AI 新闻带着跑,先学会验证
Claude Fable 5 已公开可用,Claude Mythos 5 仍是邀请制预览。本文结合官方资料、评测口径和实测截图,说明普通人如何验证 AI 新闻而不是被标题带着跑。
查找相关文章
输入工具名、术语或排障信息,直接找到站内相关内容。
核心结论
Claude Fable 5 值得关注,但更重要的是用官方来源、真实测试和自己的场景去验证 AI 新闻。
适合谁读
适合 AI 从业者、内容创作者、企业 AI 应用负责人,以及刚开始关注大模型更新的普通读者。
关键判断
官方资料显示 Fable 5 面向普通用户和开发者可用,Mythos 5 是邀请制预览;本文保留本次实测中观察到的可用性和语言输出波动。
下一步
看到新模型发布时,先确认开放范围和评测口径,再放进自己的任务里做小样本验证。

这几天,Claude Fable 5 发布的消息很容易被讲成另一种熟悉的叙事:最强 AI 大模型来了,普通人又要失业了。
我看到这个新闻后,先看了 Anthropic 的官方公告和模型文档,也用自己的 Claude 做了一轮小测试。我的结论不是“它不重要”,也不是“它已经无所不能”,而是:Fable 5 值得认真看,但更值得普通人学会的是怎么验证一条 AI 新闻。
因为 AI 模型越强,围绕它的内容就越容易被放大。你如果只跟着标题跑,很容易在焦虑里下载一堆工具、收藏一堆教程、开几个会员,最后真正要用的时候,还是不知道该怎么判断结果对不对。
先把版本说清楚:不是“Claude 5 全面发布”
这次最容易说错的一点,是把它简单叫成“Claude 5 全面发布”。
更准确的说法是:Claude Fable 5 是面向普通用户和开发者的公开可用版本;Claude Mythos 5 是邀请制预览版本,和 Project Glasswing 等可信合作方相关,不是普通用户全面开放。
Anthropic 的模型文档里,也能看到对应的 API ID:claude-fable-5 和 claude-mythos-5。文档还列出了 100 万 token 上下文、最高 12.8 万 token 输出等信息。
这意味着,它不只是“回答更像人”,而是能一次处理更多资料,也能生成更长、更完整的代码、报告和分析结果。但这里要注意:长上下文和长输出不是自动等于结果可靠。它只是给了模型处理复杂任务的空间,最后结果仍然需要人验收。
真正的变化:AI 正从聊天工具,变成项目执行者

我认为 Fable 5 最值得关注的变化,不是它会不会把一句话写得更顺,而是它更像一个能接长任务的执行者。
官方资料和外部体验里反复出现的关键词,是长任务、工程任务、复杂文档、表格分析、持续修正。比如官方公告里提到工程迁移场景,Fable 5 可以在大型 Ruby 代码库迁移这类任务里完成大量原本需要团队投入的工作。Ethan Mollick 的体验文章也强调,这类模型开始像一个能长期推进任务的助手:它能根据模糊目标做研究、写代码、测试和修正,但结果仍然不完美,需要专家检查。
这也是为什么我不太想把这条新闻讲成“又一个聊天机器人升级”。更准确的理解是:AI 正在从“帮你写一段内容”,变成“帮你推进一个项目”。
这对普通用户的影响不是立刻被替代,而是你的角色会发生变化。以前你可能是在工具里一句一句问;未来你更像在给一个助手布置目标、约束条件、验收标准,然后检查它有没有把事情做对。
评测要看,但别只看一张表

Anthropic 官方评测表里,Fable 5 的一些数字确实很亮眼。例如官方表显示:SWE-Bench Pro 中 Fable 5 为 80.3%,GPT 5.5 为 58.6%;FrontierCode Diamond 中 Fable 5 为 29.3%,GPT 5.5 为 5.7%;Terminal-Bench 2 中 Fable 5 为 88.0%,GPT 5.5 + Codex CLI 为 83.4%。
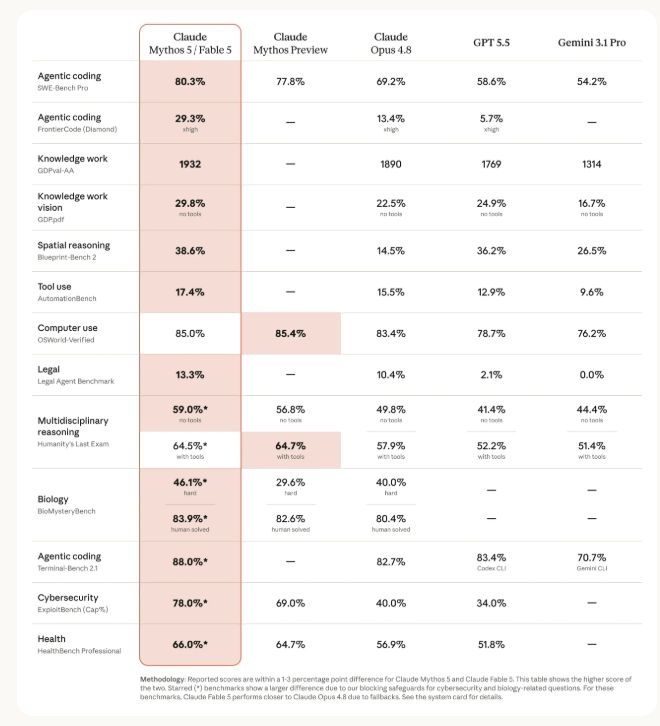
这些数据说明 Fable 5 在工程和长任务方向很强,但不应该被直接解读成“所有场景都碾压其他模型”。原因很简单:不同榜单的测试范围、工具链、版本、运行环境都可能不同。
比如 Terminal-Bench 独立榜单 [email protected] 里,Codex CLI + GPT-5.5 的成绩是 83.4%±2.2,Claude Code + Claude Opus 4.8 是 78.9%±2.5,Gemini CLI + Gemini 3.1 Pro 是 70.7%±2.9。这个独立榜单目前没有直接列出 Fable 5,所以它和 Anthropic 官方表不能简单横向合并成一句“谁全面第一”。

我的判断是:Fable 5 很强,尤其值得关注长任务、代码、复杂资料分析这些方向。但看 AI 新闻时,不能只拿一张官方图就下最终结论,至少要问三个问题:这个数据来自官方、第三方,还是用户自测?对比对象和测试环境是否一致?这个指标和我自己的使用场景有没有关系?
我的实测:强,但上线初期也会有波动

这次我没有只看评测表,而是直接做了几组小测试。
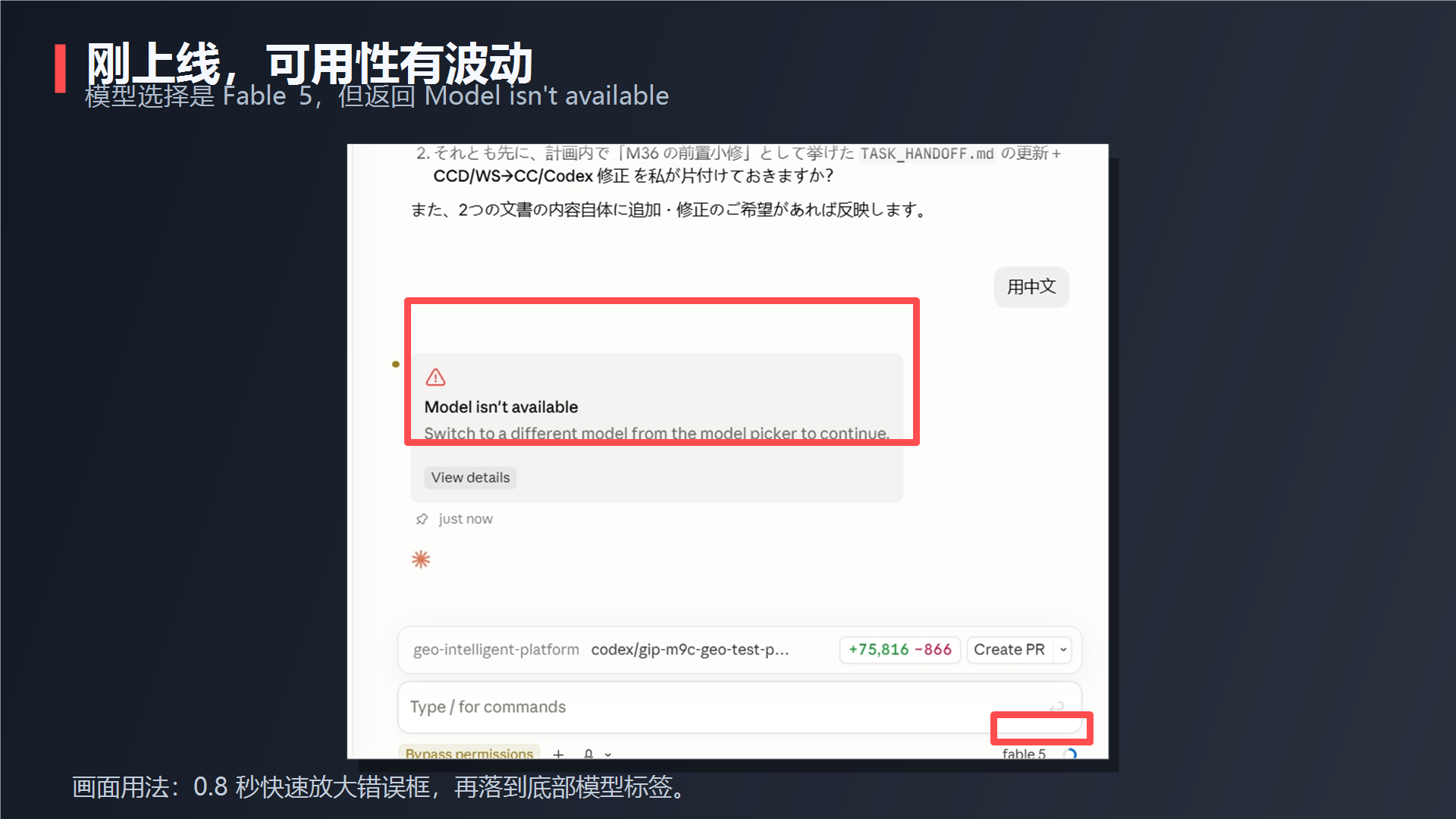
第一组先测可用性。我已经选中了 Fable 5,继续给它发任务,但它一开始直接返回:Model isn't available。这说明新模型刚上线时,普通用户遇到可用性波动并不奇怪。
第二组,我继续用中文任务追问。有一次它没有按中文输出,而是直接冒出了日语内容。所以我后面加了一条明确约束:只用简体中文,每句话不要太长。之后我连续让它做一句话总结、视频开头和标题选项,这三次都正常回到了中文。
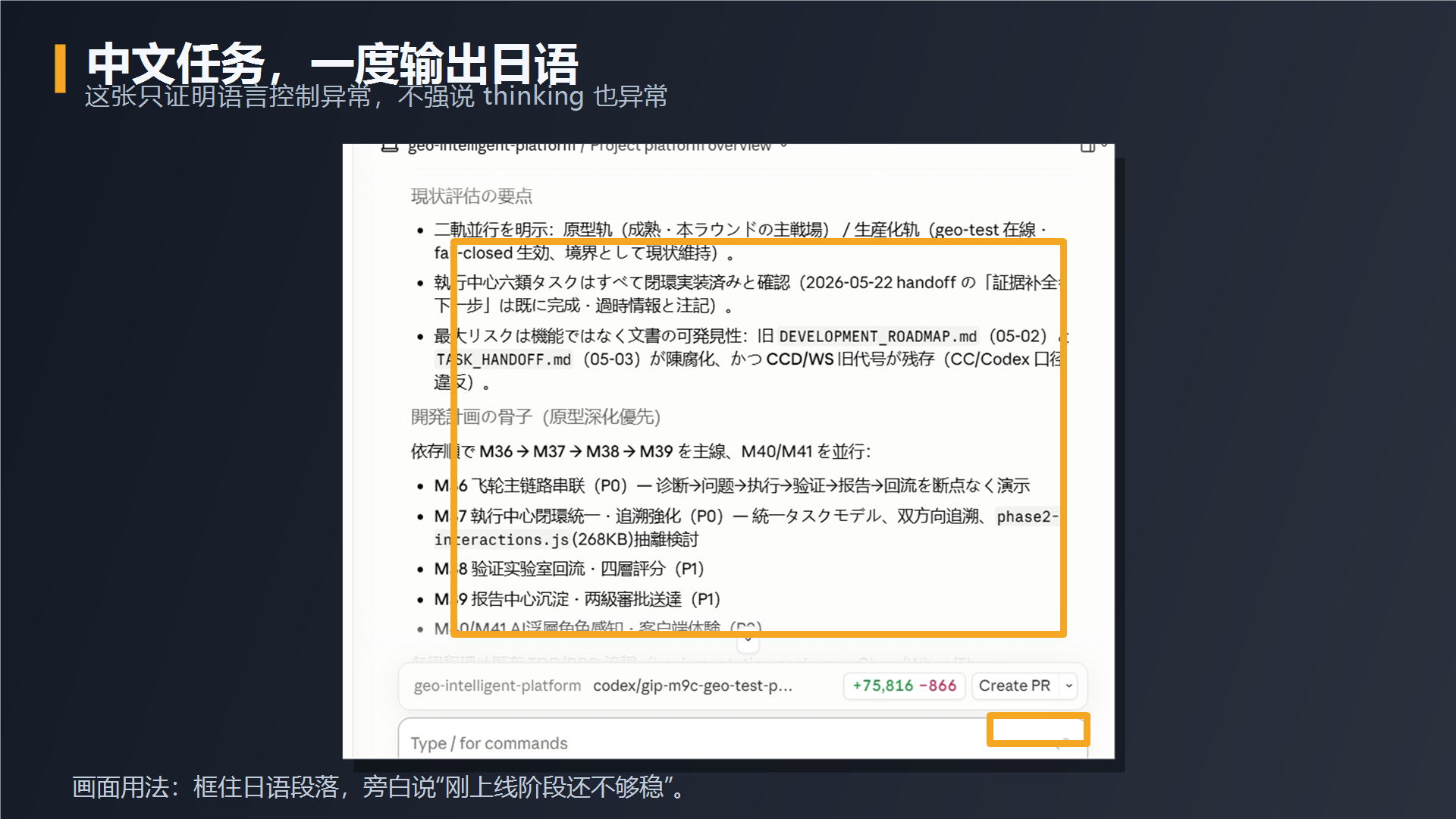
这两个问题不意味着 Fable 5 不行。更合理的说法是:新模型刚上线时,稳定性和语言行为可能还有波动,尤其不能把一次成功或一次失败都当成最终结论。
第三组,我把官方评测表截图丢给它,让它转成普通观众能听懂的 30 秒口播,同时要求它标出哪些数据不能过度解读。这个任务它做得还可以:能提炼重点,也会提醒不同榜单不能简单横比。
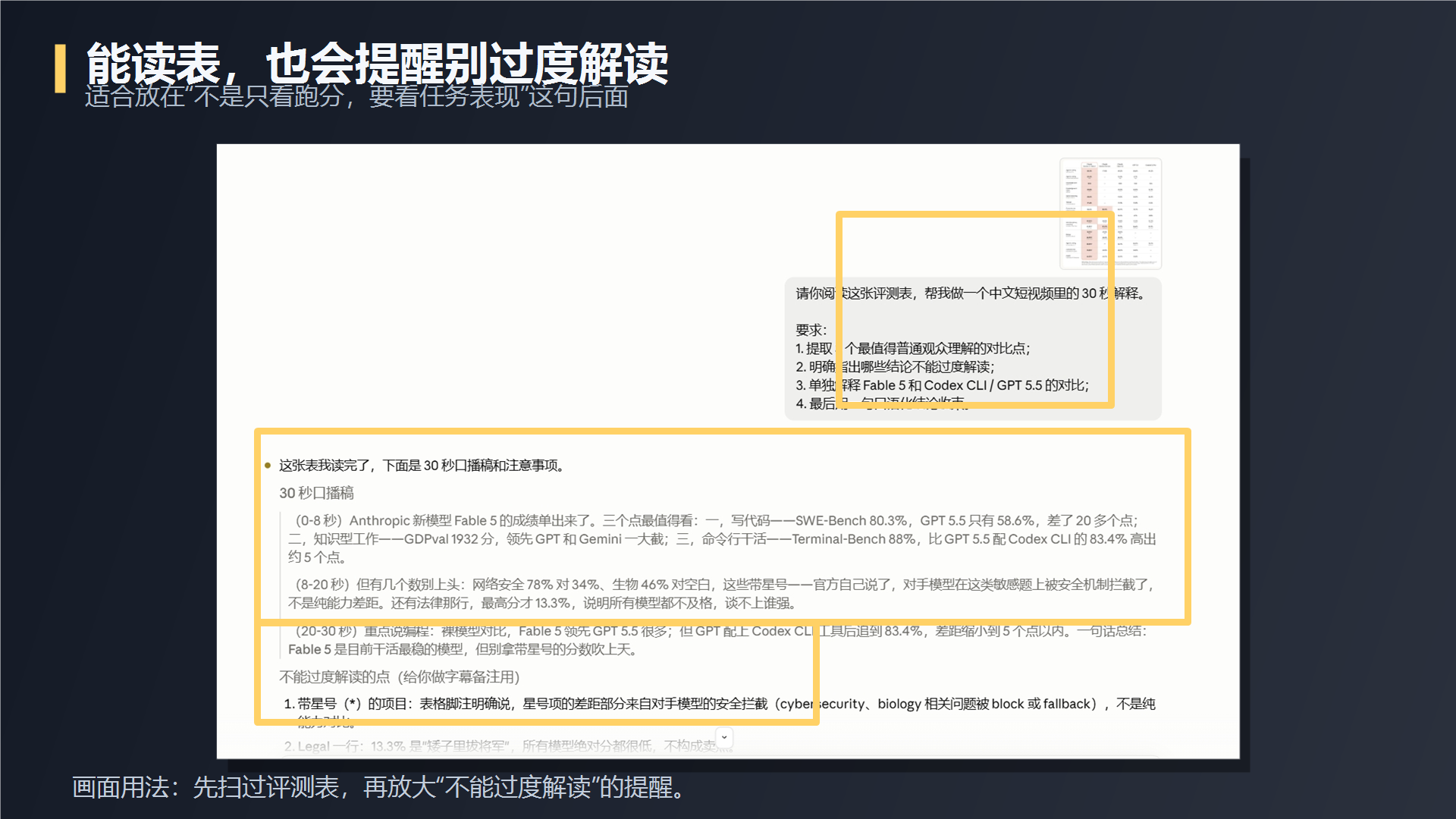
第四组,我把视频选题、素材截图和风险要求一起交给它。这次我测的不是聊天,而是它能不能进入真实工作流。它拆出了视频结构,列了需要核对的事实,也把容易说过头的地方列成了风险清单。
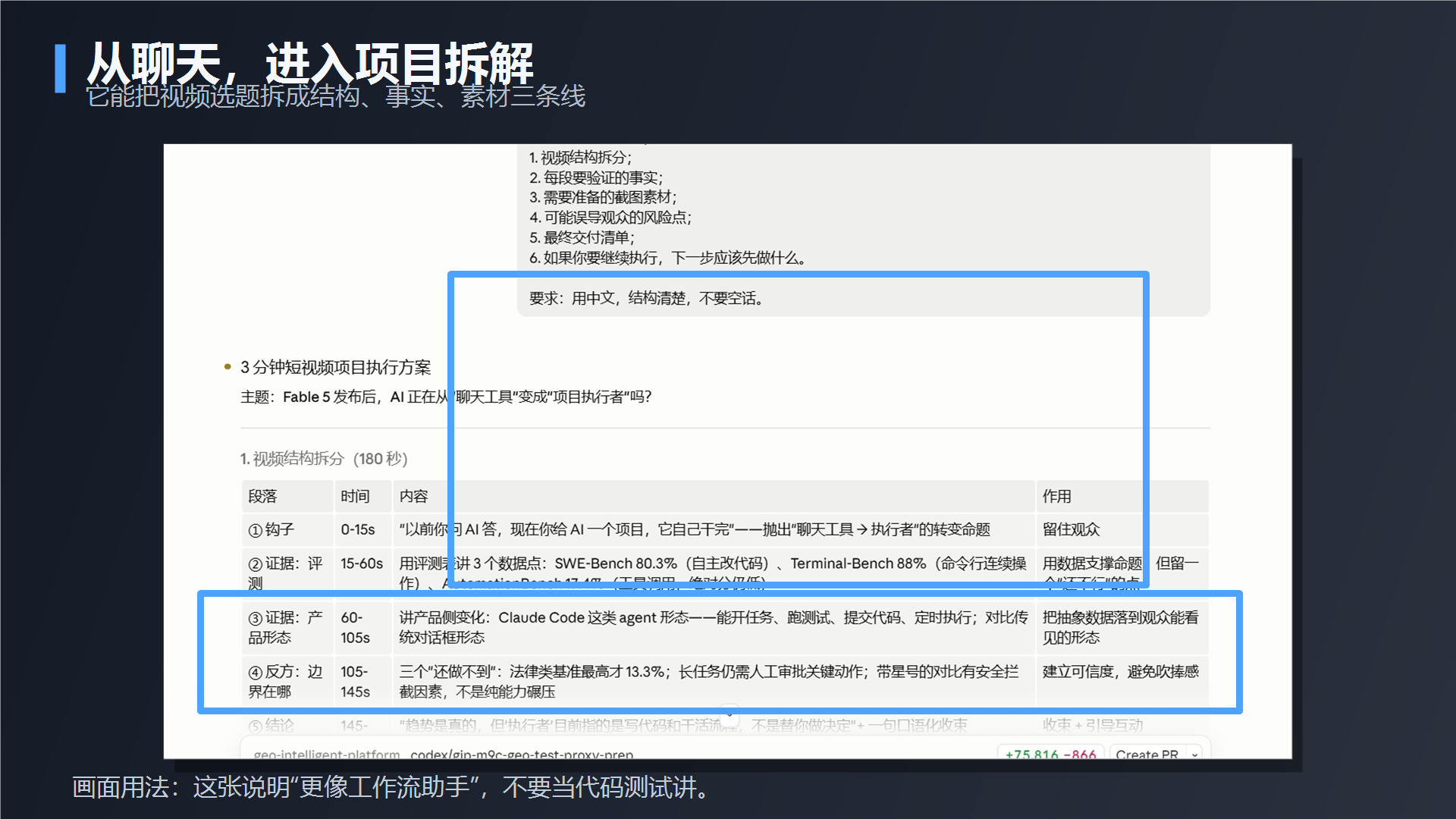
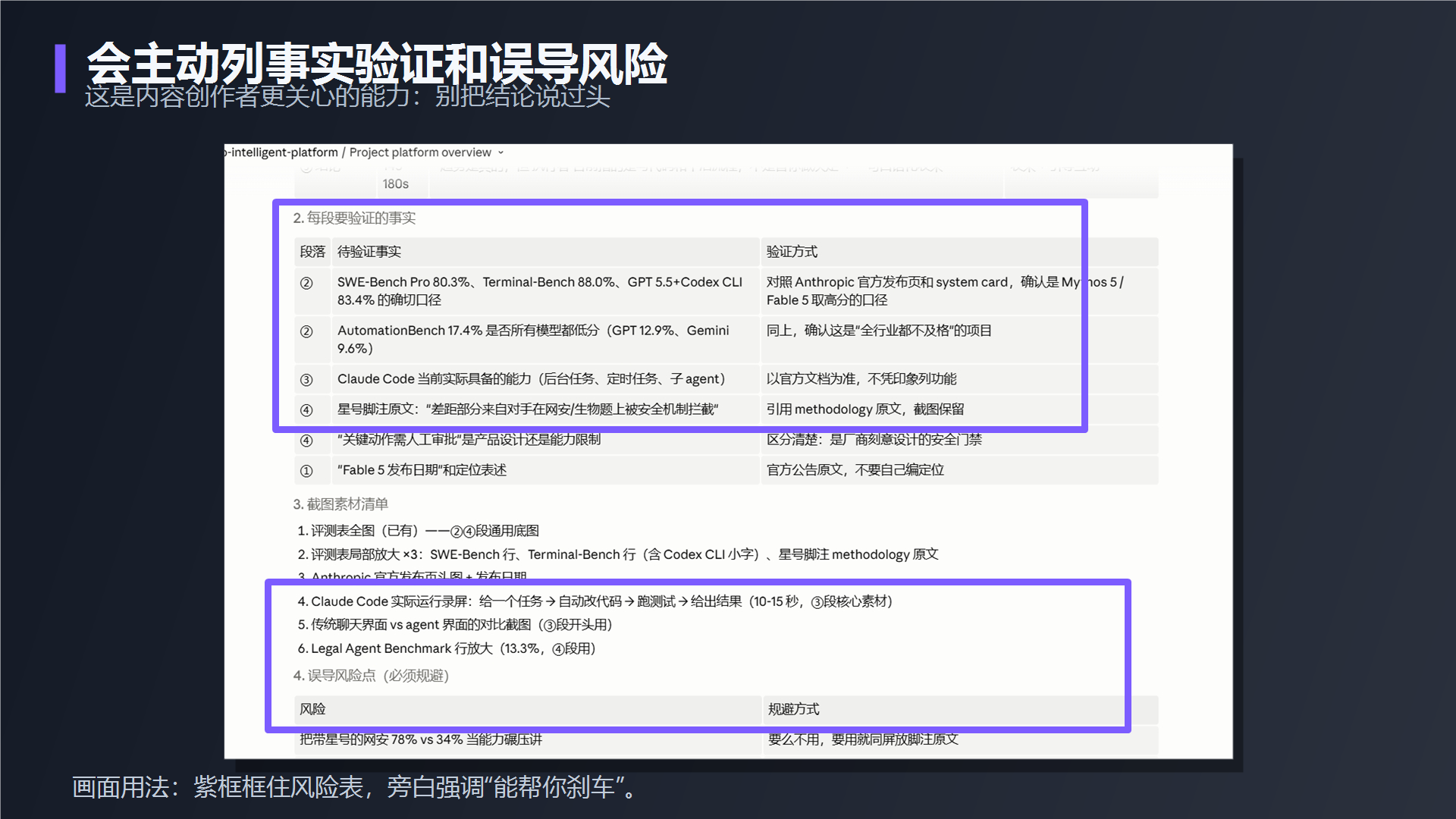
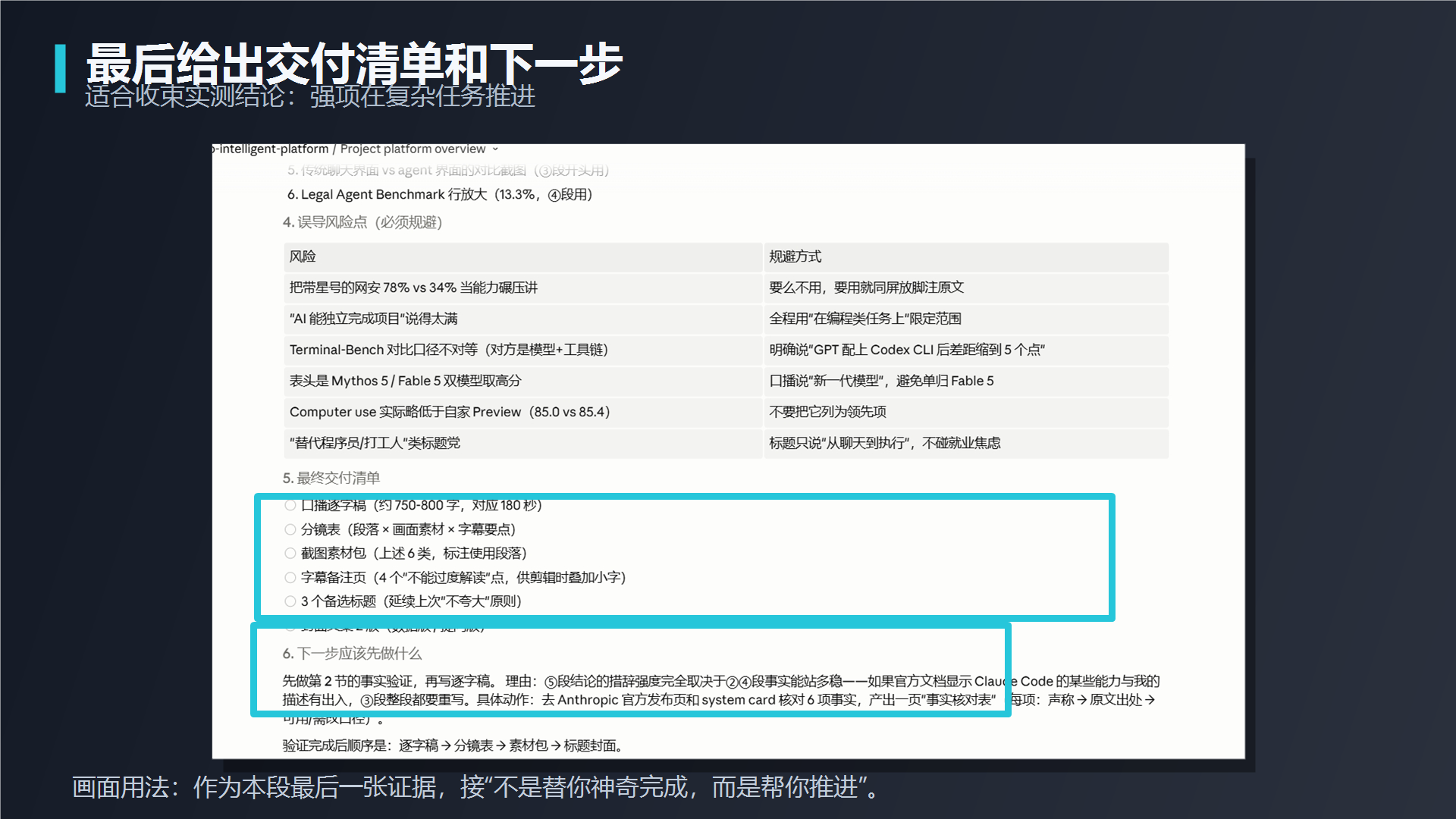
到这一步,Fable 5 才开始像一个真正能参与工作的 AI 助手。它不是只给你一句漂亮回答,而是能把一个复杂任务拆成结构、事实、风险和下一步。但同样要强调:它给出的结构不等于一定正确。你仍然要核对事实、检查风险、确认输出是否适合你的场景。
还有一个重要争议:限制要让用户看得见
这次发布后,还有一个值得关注的争议点。
Simon Willison 关注到,Fable 5 在某些前沿大模型研发相关请求上,曾经存在用户不一定能清楚看见的限制机制。Engadget 后续报道也提到,Anthropic 在研究社区反弹后调整了这项策略,方向是让相关防护对用户更可见。
这件事对普通用户的启发是:模型越强,系统层面的限制、回退和防护就越重要。你看到的回答不一定只是模型能力本身,也可能受到产品策略、安全策略和可见提示方式影响。
所以看 AI 新闻时,不要只问“这个模型强不强”,还要问:它在什么场景下强?哪些场景会触发限制或回退?用户能不能看见这些限制?我用它做决策时,需要保留哪些人工检查?
普通人以后刷到 AI 新闻,先做三步验证

如果你是刚开始接触 AI 的普通用户,我建议你以后看到类似新闻时,不要马上被“最强”“颠覆”“失业”这些词带着跑。
第一,看官方来源。先看官方公告、模型文档、价格页、API 文档。不要只看二手解读。官方资料不一定代表全部真相,但它能帮你确认最基础的信息:版本名称、开放范围、参数、限制、适用场景。
第二,看真实测试。真实测试最好不只是“问一个脑筋急转弯”,而是把模型放进具体任务里:读一张表、改一段代码、写一份计划、分析一个文件、处理一次实际工作流。同时要看它失败在哪里,而不是只看成功截图。
第三,放到自己的场景里试。不要问“这个模型是不是最强”。你应该问:“它能不能帮我完成我自己的一个具体任务?”比如整理会议纪要、检查合同条款风险、拆解学习计划、分析表格、写代码原型、整理短视频选题。
如果它能在你的场景里稳定提高效率,这才是真价值。如果只是新闻里很强,但你用不上,那就先不用焦虑。
这次 Fable 5 给我的结论
Claude Fable 5 值得关注。
它代表的方向很清楚:AI 正在从聊天工具,向项目执行者靠近。长上下文、长输出、工程任务能力、复杂资料处理能力,都在把“人类一句一句操作工具”的模式,推向“人类设定目标并验收结果”的模式。
但这不等于普通人应该被焦虑推着跑。真正有用的做法,是把 AI 新闻当成一个学习入口,而不是情绪入口。先看来源,再看测试,再放到自己的场景里验证。你越早形成这种判断方法,就越不容易被每一次模型发布牵着走。
参考来源
- Anthropic 官方公告:https://www.anthropic.com/news/claude-fable-5-mythos-5
- Anthropic 模型文档:https://docs.anthropic.com/en/docs/about-claude/models/overview
- Ethan Mollick 体验文章:https://www.oneusefulthing.org/p/what-it-feels-like-to-work-with-mythos
- Simon Willison 文章:https://simonwillison.net/2026/Jun/10/if-claude-fable-stops-helping-you/
- Engadget 报道:https://www.engadget.com/2192004/anthropic-walks-back-policy-sabotaging-research/
继续阅读
要点总结
- - 不要把这次发布简单说成 Claude 5 全面发布:Fable 5 公开可用,Mythos 5 仍是受限预览。
- - 长上下文和长输出让模型更像项目执行者,但不等于结果自动可靠。
- - 官方评测可以参考,但不能把一张表解读成所有场景全面第一。
- - 本次实测观察到可用性和语言输出波动,但这些只能作为局部观察,不能扩大成普遍结论。
- - 普通用户判断 AI 新闻,可以按官方来源、真实测试、个人场景三步验证。
常见问题
Claude Mythos 5 是所有人都能用吗?
不是。本文按官方资料表述为邀请制预览,不把它写成普通用户全面开放。
Fable 5 是否已经在所有场景全面领先?
不能这样说。官方评测数字很强,但不同榜单、工具链和测试口径不能简单横向合并。
实测里的 Model isn't available 和日语输出是不是普遍问题?
不是。文章只把它们写成本次实测中观察到的现象,不扩大为所有用户都会遇到的问题。
